10.2 Proximal Policy Optimization (PPO)
Mathematical Intuition
TRPO’s Main Drawback
TRPO’s main drawback has to do with the calculation of the Hessian matrix with respect to the KL-Divergence:
\[ \mathbf{H} = \nabla^2 D_{KL}(\pi_{\theta_{t}} \| \pi_{\theta_{t+1}}) \]
Proximal Policy Optimization (PPO)

OpenAI 2017
Link to Research Paper
PPO: Surrogate Objectives
PPO KL-Divergence Penalty:
\[ L^{\text{KL}}(\pi_{\theta_{t+1}}) = \mathbb{E} \left[ \frac{\pi_{\theta_{t+1}}(a|s)}{\pi_{\theta_{t}}(a|s)} \hat{A}_t - \beta D_{KL}(\pi_{\theta_{t}} \| \pi_{\theta_{t+1}}) \right] \]
PPO Clip:
\[ L^{\text{CLIP}}(\pi_{\theta_{t+1}}) = \mathbb{E} \left[ \min \left( \frac{\pi_{\theta_{t+1}}(a|s)}{\pi_{\theta_{t}}(a|s)} \hat{A}_t, \text{clip}\left(\frac{\pi_{\theta_{t+1}}(a|s)}{\pi_{\theta_{t}}(a|s)}, 1-\epsilon, 1+\epsilon\right) \hat{A}_t \right) \right] \]
Gaussian Policy
\[ \begin{aligned} \mu(s), \sigma(s) &= \theta_{\mu, \sigma}(s) \\ \pi(a|s; \theta) &= \frac{1}{\sqrt{2 \pi \sigma^2(s)}} \exp\left(-\frac{(a - \mu(s))^2}{2 \sigma^2(s)}\right) \end{aligned} \]
Proximal Policy Optimization: Illustration
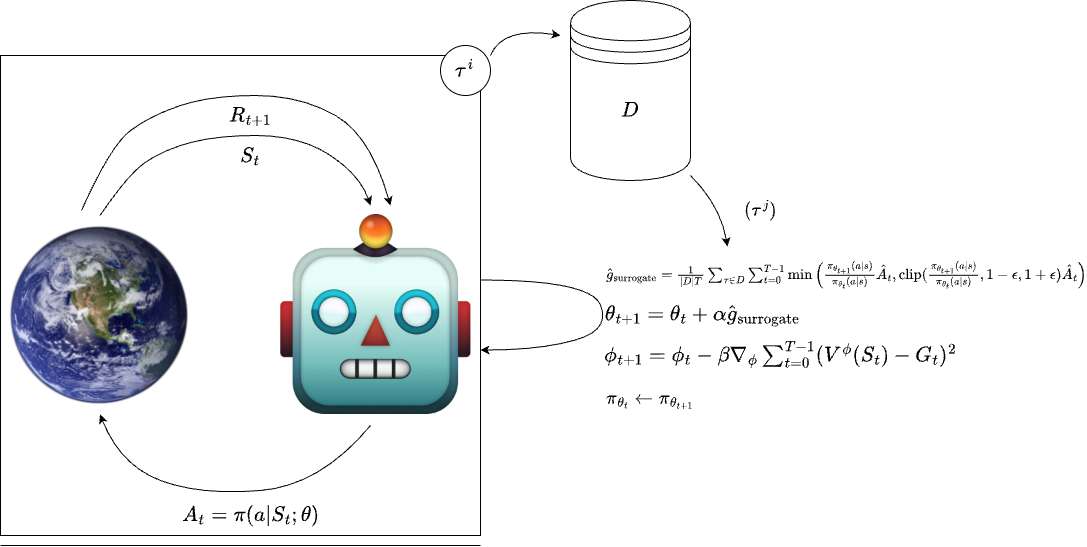
Proximal Policy Optimization: Pseudocode

Exercise
What is the key mathematical difference between the true policy gradient and a surrogate policy gradient in reinforcement learning?
\[ L(\pi_{\theta_{t+1}}) = F(\pi_{\theta_{t}}) + \mathbb{E}_{s \approx \rho_{\pi_{\theta_{t}}}, a \approx \pi_{\theta_{t}}} \left[\frac{\pi_{\theta_{t+1}}(a|s)}{\pi_{\theta_{t}}(a|s)} \hat{A}_t\right] \]