7.3 On-Policy Function Approximation
Limits of Off-Policy Approximation
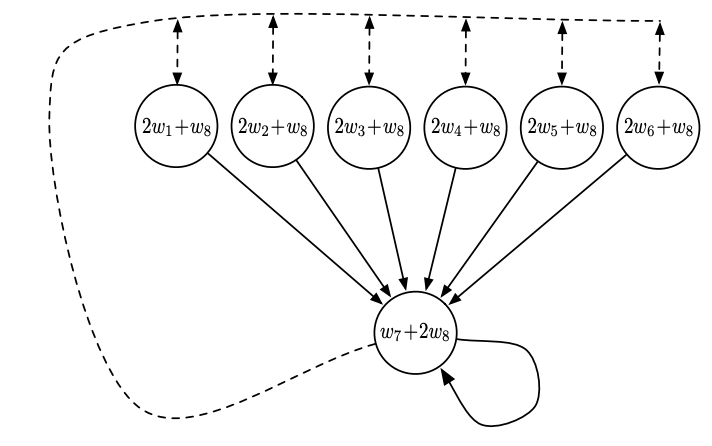
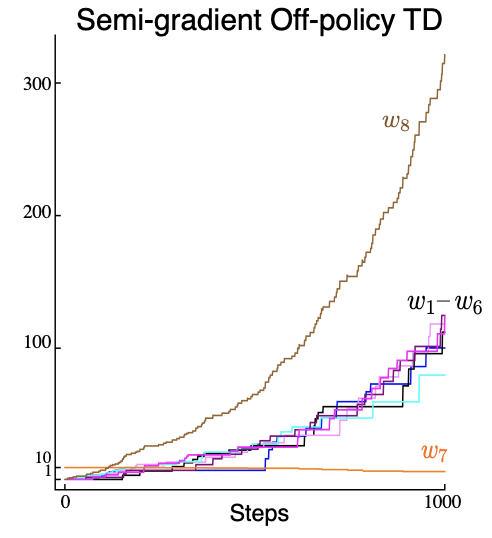
Limits of Off-Policy Approximation
Convergence of control algorithms:
| Algorithm | Tabular | Linear | Neural Networks |
|---|---|---|---|
| Monte-Carlo Control | ✅ | (✅) | ❌ |
| SARSA | ✅ | (✅) | ❌ |
| Q-learning | ✅ | ❌ | ❌ |
Convergence of control algorithms:
| Algorithm | Tabular | Linear | Neural Networks |
|---|---|---|---|
| Monte-Carlo Control | ✅ | (✅) | ❌ |
| SARSA | ✅ | (✅) | ❌ |
| Q-learning | ✅ | ❌ | ❌ |