12.1 Advanced Topics in Reinforcement Learning
Imitation Learning
- Learn a policy \(\pi(a|s)\) by mimicking an expert’s demonstrations, \((s, a)\), without requiring explicit reward signals.
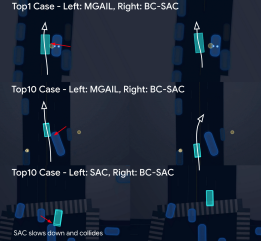
Application: Autonomous Driving
Link to Research Paper
Inverse Reinforcement Learning
- Infer the reward function \(R(s, a)\) given expert trajectories to derive an optimal policy, \(\pi^*\).
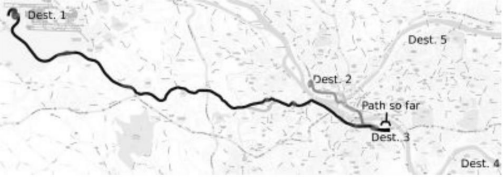
Application: Predicting Driver Behavior and Route Recommendation
Link to Research Paper
Offline Reinforcement Learning
- Learn a policy \(\pi(a|s)\) from a fixed dataset \(D = \{(s, a, r, s')\}\) without further environment interaction.
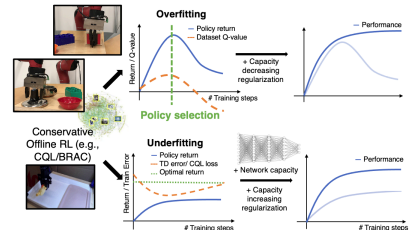
Application: Robotic Manipulation
Link to Research Paper
Multi-Agent Reinforcement Learning
- Optimize multiple agents’ policies \(\pi_i(a|s)\) interacting in a shared environment, considering cooperation or competition.
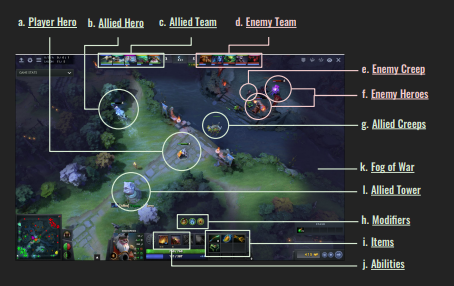
Application: Strategic Game-play in Dota2
Link to Research Paper
Hierarchical Reinforcement Learning
- Decompose tasks into a hierarchy of policies, \(\pi_\text{high}(g|s)\) for goals and \(\pi_\text{low}(a|s, g)\) for actions.

Application: MuJoCo Ant Maze Path Finding
Link to Research Paper
Multi-Objective Reinforcement Learning
- Optimize a policy \(\pi(a|s)\) under multiple conflicting objectives, \(\{R_1, R_2, \dots\}\)

Application: Resource Allocation
Link to Research Paper
Meta Learning
- Train agents to quickly adapt to new tasks \(\mathcal{T}\) by optimizing over task distributions \(p(\mathcal{T})\).
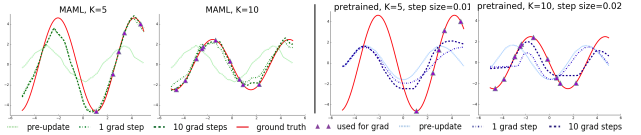
Application: Few Shot Learning
Link to Research Paper