Homework 4
Instructions:
- Show ALL Work, Neatly and in Order.
- No credit for Answers Without Work.
- Submit a single PDF file including all solutions.
- DO NOT submit individual files or images.
- For coding questions, submit ONE.pyfile with comments.
For this homework, you only need numpy, matplotlib, gymnasium & pygame.
![]()
Question 1
If the current state is \(S_{t}\) and actions are selected according to stochastic policy \(\pi\), then what is the expectation of \(R_{t+1}\) in terms of \(\pi\) and the four-argument function \(p\)?
Question 2
Give an equation for \(v_{\pi}\) in terms of \(q_{\pi}\) and \(\pi\).
Question 3
Give an equation for \(q_{\pi}\) in terms of \(v_{\pi}\) and \(\pi\).
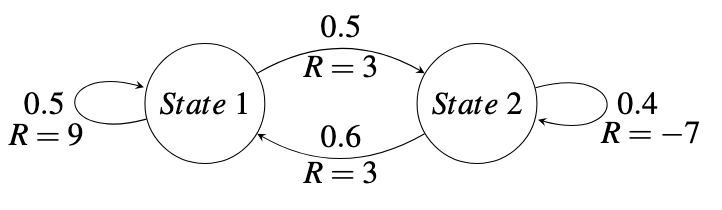
Coding Exercise 1: Markov Chain I
With a discount factor of \(\gamma = 0.9\), calculate \(v(t)\) when \(t = 100\) for the following Markov Chain:
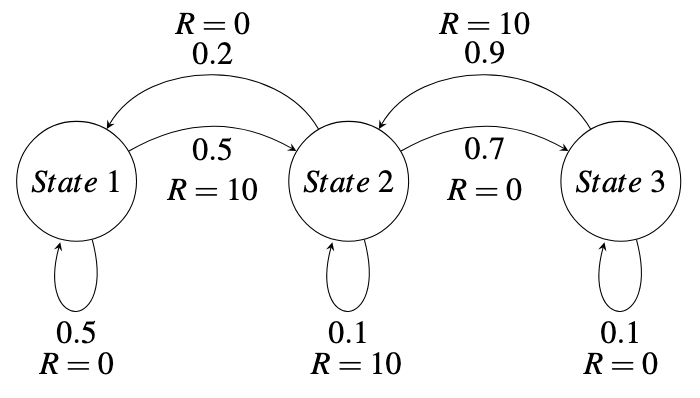
Coding Exercise 2: Markov Chain II
With a discount factor of \(\gamma = 0.9\), calculate \(v(t)\) when \(t = 100\) for the following Markov Chain:
Coding Exercise 3: Value Iteration
With a discount factor of \(\gamma = 0.9\), code Value Iteration algorithm for GridWorldEnv using the provided hyperparameters.
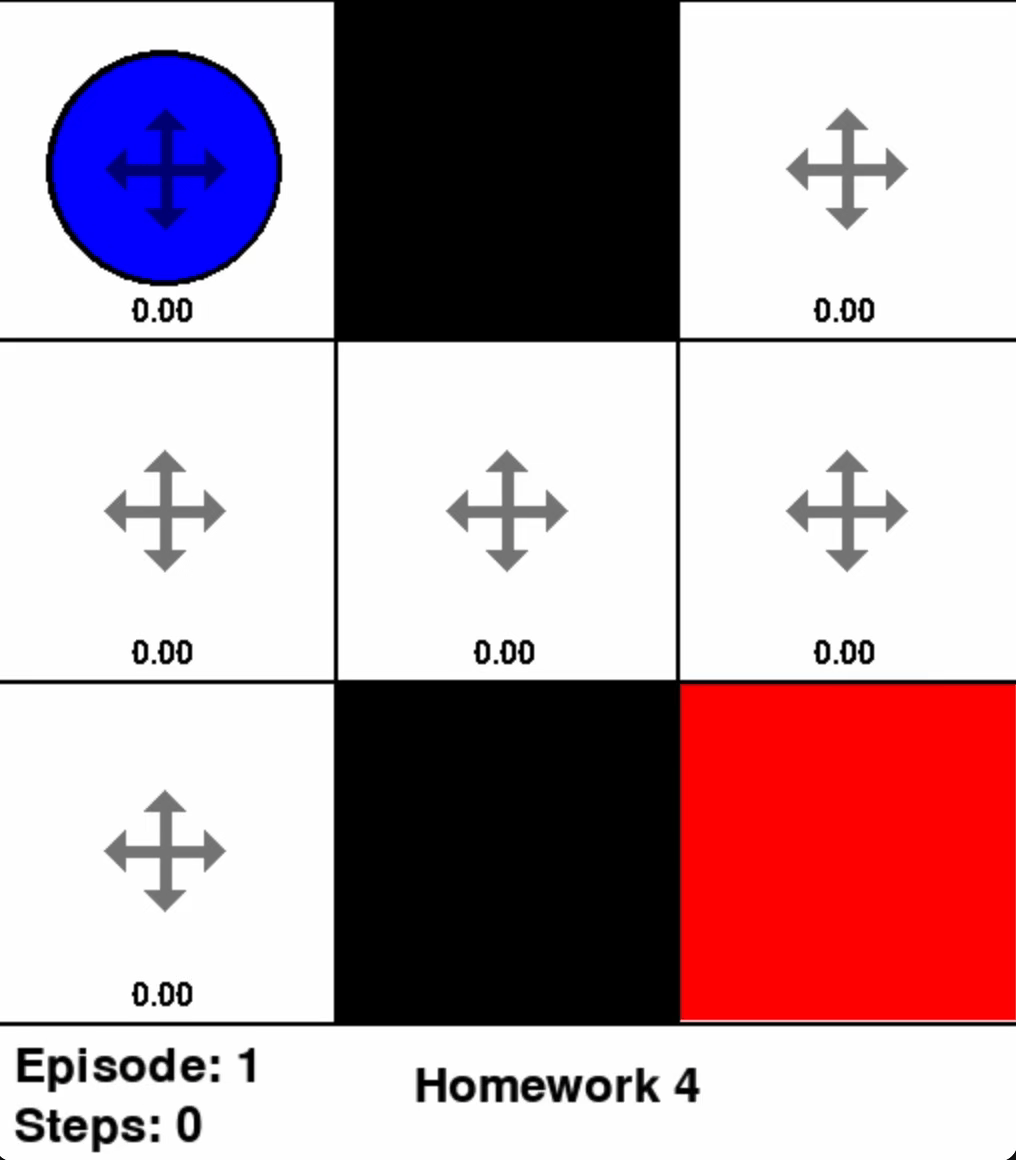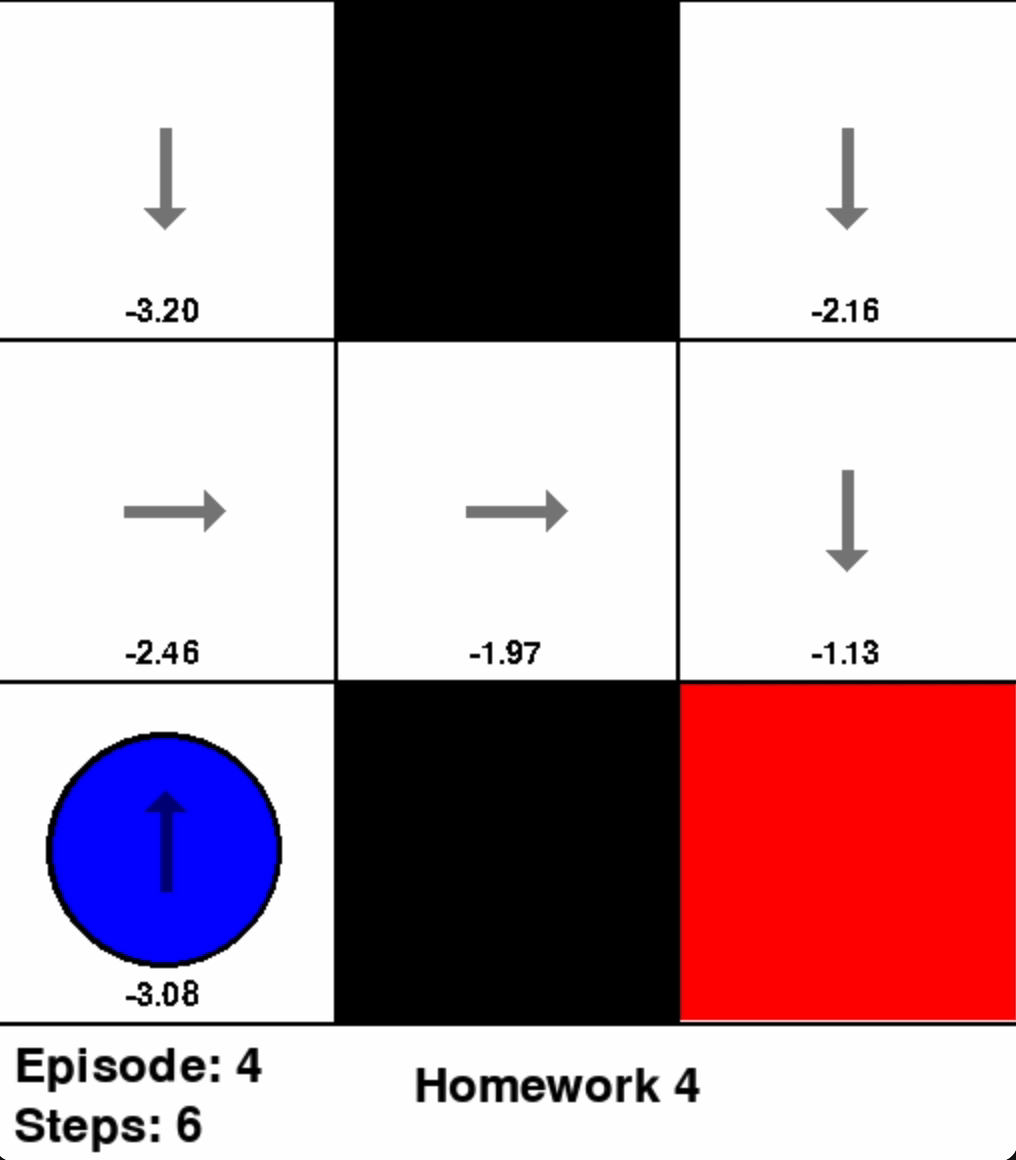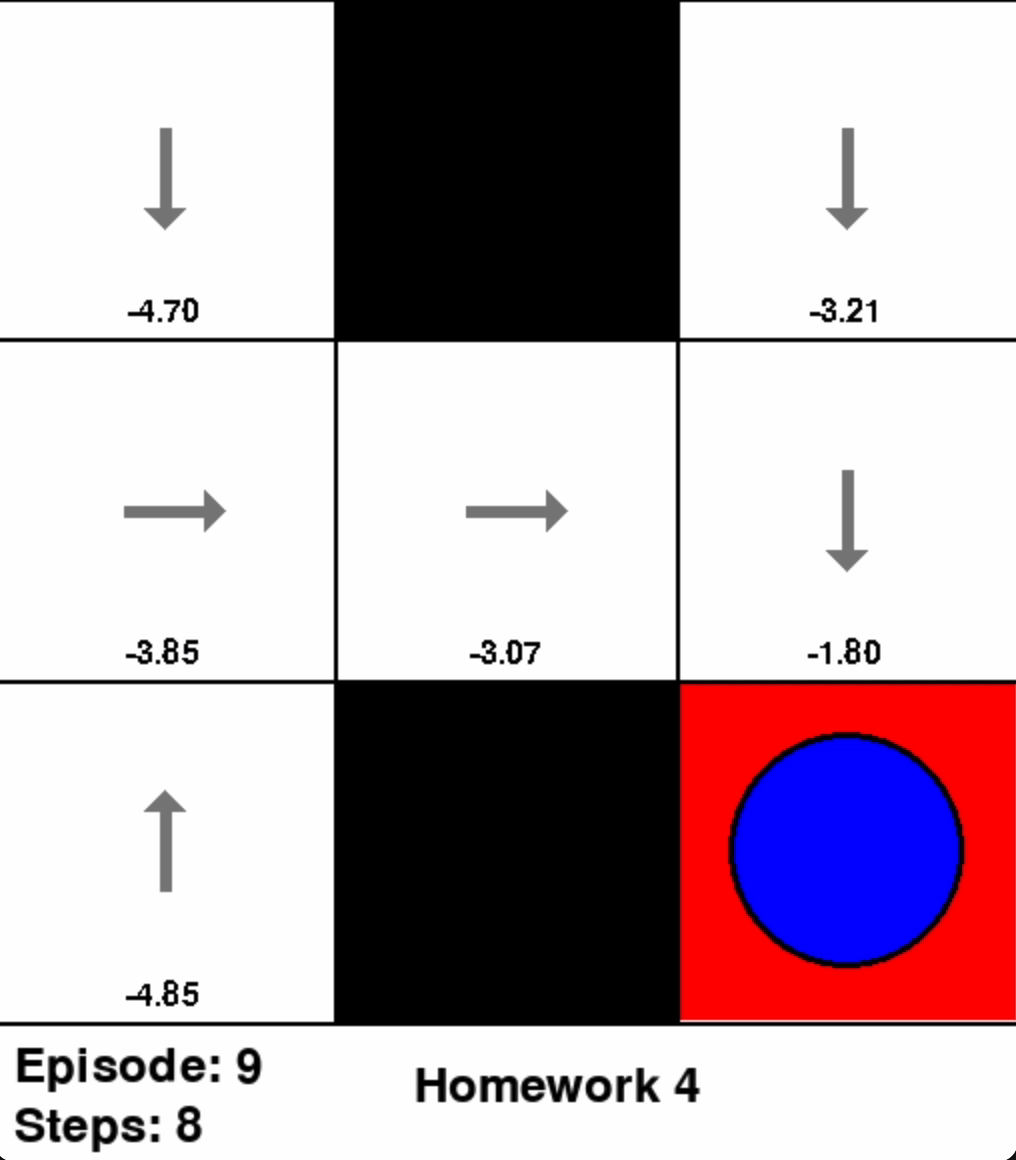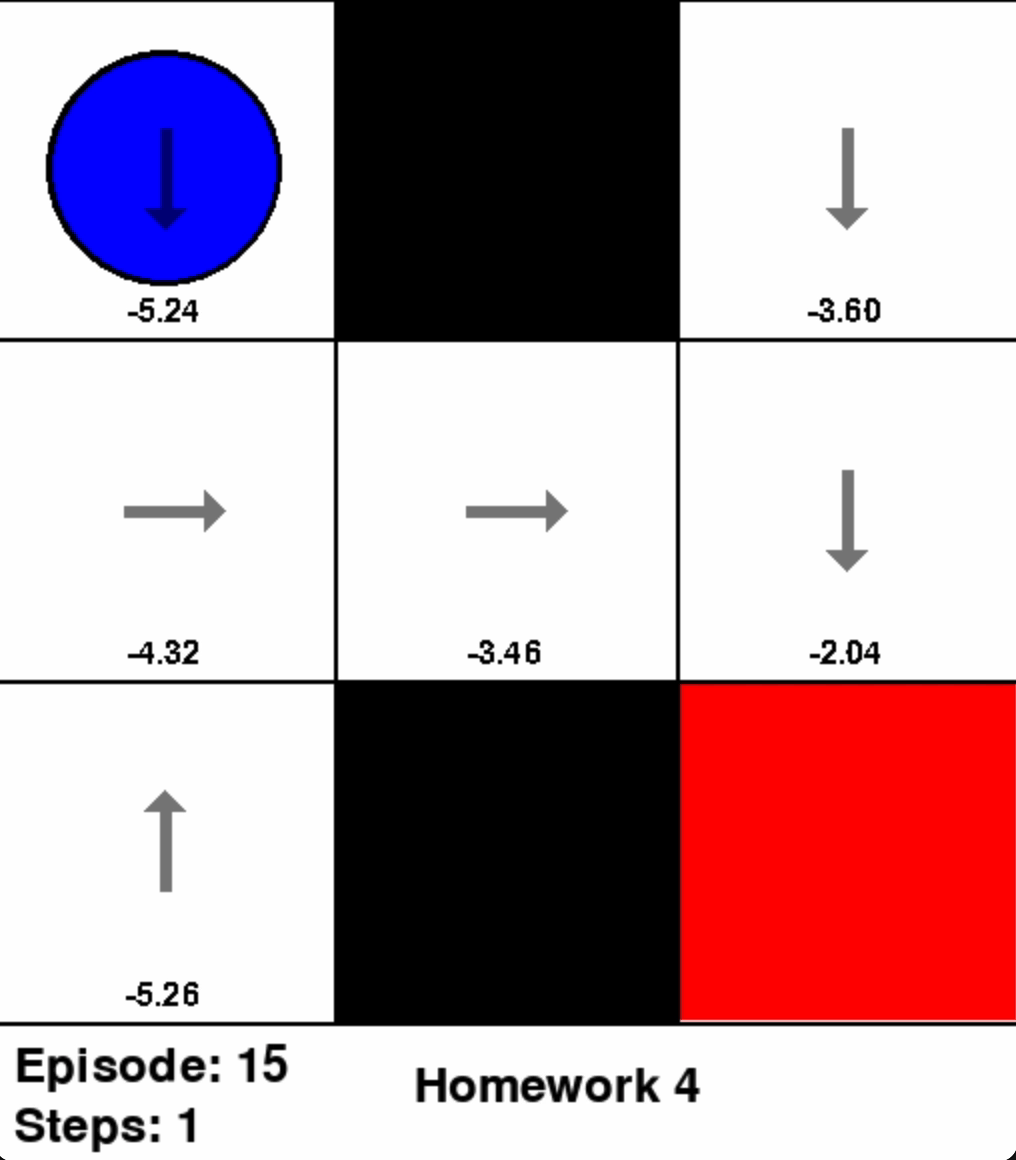
Note: The gray shaded areas are barriers. Moving into a barrier incurs a reward of \(R = -1\).