4.4 Value Iteration
Dynamic Programming is a collection of algorithms that can be used to compute optimal policies \(\pi_{*}\).
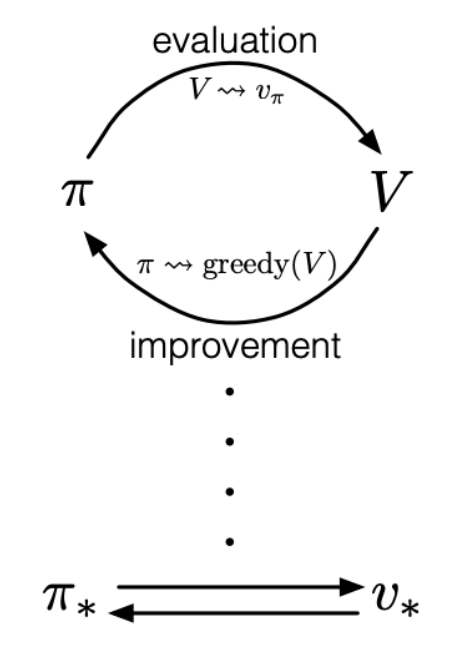
One drawback of policy iteration is that policy evaluation is done iteratively, requiring convergence exactly to \(v_{\pi}\) which occurs only in the limit.
Can we find a way to improve policies without waiting for full convergence of \(v_{\pi}\)?
Imagine your commute to work every day:
- \(S\) — The location you’re currently in (e.g., your home or a traffic junction). More generally, \(S_{1,...,k}\) can represent multiple possible locations.
- \(A_{1,...,k}\) — The route you can choose (e.g., highway, back streets, scenic route, parkway, or alternate street).
- \(R\) — Your reward could be getting to work quickly, stress-free, or on time.




Suppose you want to find the optimal route from home to work. Rather than just trying one alternative, you evaluate all possible routes from each location, estimate the expected travel time (or reward) recursively, and keep updating your estimates until they converge.
How could you systematically assign a value to each location and decide which route maximizes your overall commute reward?
Value Iteration truncates the policy evaluation step after just one sweep.

Generalized Policy Iteration (GPI) refers to the general idea of letting policy evaluation and policy improvement processes interact, regardless of anything else.
Almost all of Reinforcement Learning can be described as the policy always being improved with respect to the value function, and the value function always being driven toward the value function for the policy.